

BFS와 DFS는 그래프를 그려 그래프 안을 돌아다니며 알맞는 경우를 찾을 때 사용되는 알고리즘이다.
이 알고리즘들은 하나의 저장장소와 visited 저장 장소를 이용하여 그래프의 규칙을 찾게 된다.
BFS
BFS는 Breadth Frist Search의 약자로 말 그대로 너비 우선 탐색을 하는 알고리즘이다.
BFS는 Queue를 사용하여 경우의 수를 저장한다. 해당 queue에서 shift를 이용하여 얕은 깊이의 요소들을 우선적으로 계산을 진행한다. 이를 통하여 시작 지점에서 너비 우선적으로 반환하는 프로그램을 작성할 수 있다.
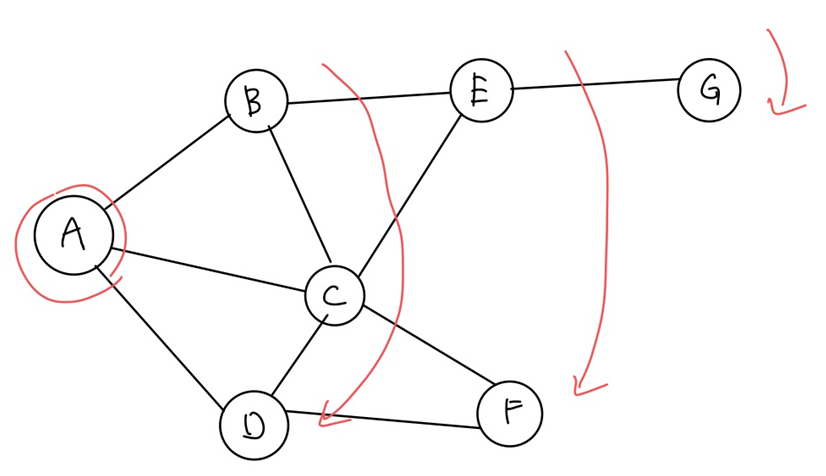
아래 그림을 보자

A지점에서 BFS 방식으로 Graph Traversals을 해보자
BFS는 queue에 저장을 하며 경우가 완료 되면 pop을 해주고, 방문하거나 접촉한 배열은 visited에 저장해준다. 여기서 Queue를 사용하므로 FIFO(first in first out)으로 진행이 된다.
진행은 아래 표와 같다.
| Queue | return | visitied |
| A | A | |
| BCD | A | ABCD |
| CDE | AB | ABCDE |
| DEF | ABC | ABCDEF |
| EF | ABCD | ABCDEF |
| FG | ABCDE | ABCDEFG |
| G | ABCDEF | ABCDEFG |
| ABCDEFG |
진행을 하고 출력된 결과를 보면 아래와 같이 가까운 곳부터 먼저 출력 되는 것을 확인 할 수 있다. 이 때문에 이 알고리즘을 BFS라 부른다.
DFS
DFS는 Depth Frist Search의 약자로 말 그대로 깊이 먼저 탐색하는 알고리즘을 의미한다. 이는 여러 어플리케이션에서도 사용되는 알고리즘이다.
그래프에서 DFS구현하는 방법은 두가지가 있다.
- recursion : call stack을 이용한다.
- interation : stack을 이용한다.
두 구현 모두 스택을 사용하므로 FILO(first in last out)을 이용한다.
DFS도 위 Graph Traversal을 진행하면 아래와 같다.
| Queue | return | visitied |
| A | A | |
| BCD | A | ABCD |
| ECD | AB | ABCDE |
| GCD | ABE | ABCDEG |
| CD | ABEG | ABCDEG |
| FD | ABEGC | ABCDEGF |
| D | ABEGCF | ABCDEGF |
| ABEGCFD | ABCDEGF |
이를 그림으로 나타내면 아래와 같다.
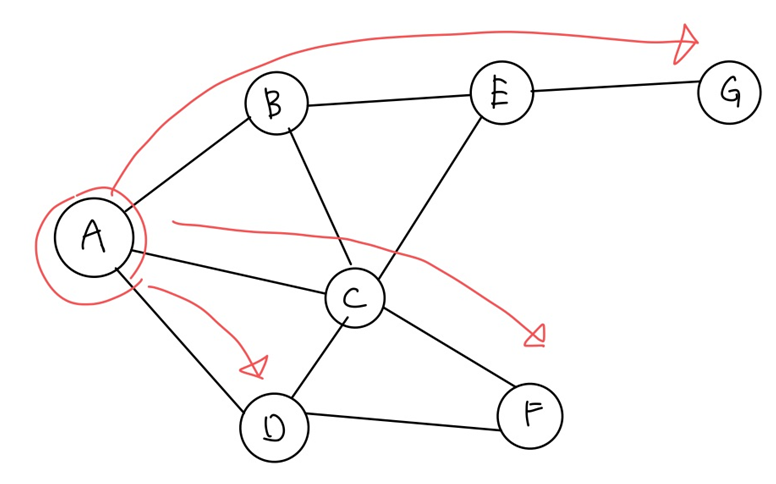
이전의 BFS와는 다르게 깊이가 깊은 곳부터 먼저 출력이 되는 것을 확인 할 수 있다.
이를 통해서 DFS는 깊이가 깊은 곳부터 출력한다는 것을 알 수 있다.
'algorithm > theory' 카테고리의 다른 글
| 소수(Prime number) 판별법/ javaScript (0) | 2023.06.01 |
|---|---|
| 순열/조합 (Permutation / Combination) (0) | 2022.11.05 |
| 탐욕법(Greedy) (0) | 2022.11.05 |
| 해쉬(Hash) (0) | 2022.11.05 |
| 동적계획법(Dynamic Programming) (0) | 2022.11.05 |